
BIO
I am a Research Scientist at NVIDIA in the Deep Imagination Research group, where I work on NVIDIA Cosmos suite of world foundation models. At the moment, I am interested in enabling spatial understanding, reasoning and forecasting through multimodal understanding (VLMs) or generation (world-model) models.
I earned my Ph.D. in Computer Science in August 2024 at Georgia Tech, where I was advised by Prof. Judy Hoffman. During my Ph.D., I broadly worked on distribution shift problems in computer vision. My doctoral thesis (here) was focused on utilizing synthetic data to train robust and reliable vision models.
[Past Life]I also actively participate in reviewing for top computer vision and machine learning conferences & workshops (have accumulated a few reviewer awards - CVPR 2023, CVPR 2022, CVPR 2021, ICLR 2022, MLRC 2021, ICML 2020, NeurIPS 2019, ICLR 2019, NeurIPS 2018 - in the process).

2012-2016
Winter 2014

2016-2017

2017-2024
Summer 2018
Summer 2020, 2022
Achievements
Read More |
News
Read More |
Research
Cosmos-Embed1: A Joint Video-Text Embedding Model for Physical AI NVIDIA (Prithvijit Chattopadhyay: Core Contributor) Huggingface 2025 [Project Page] [Huggingface] [TL;DR]

Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning NVIDIA (Prithvijit Chattopadhyay: Core Contributor) ArXiv 2025 [Project Page] [Video] [PDF] [Code] [Huggingface] [TL;DR]

Cosmos-Predict1: Cosmos World Foundation Model Platform for Physical AI NVIDIA (Prithvijit Chattopadhyay: Core Contributor) ArXiv 2025 Best of AI & Best of CES Winner, CES 2025 [Project Page] [Video] [PDF] [Code] [Models] [Press] [TL;DR]

SkyScenes: A Synthetic Dataset for
Aerial Scene Understanding
Sahil Khose*, Anisha Pal*, Aayushi Agarwal*, Deepanshi*,
Judy Hoffman, Prithvijit
Chattopadhyay
ECCV 2024
[PDF]
[Data]
[TL;DR]

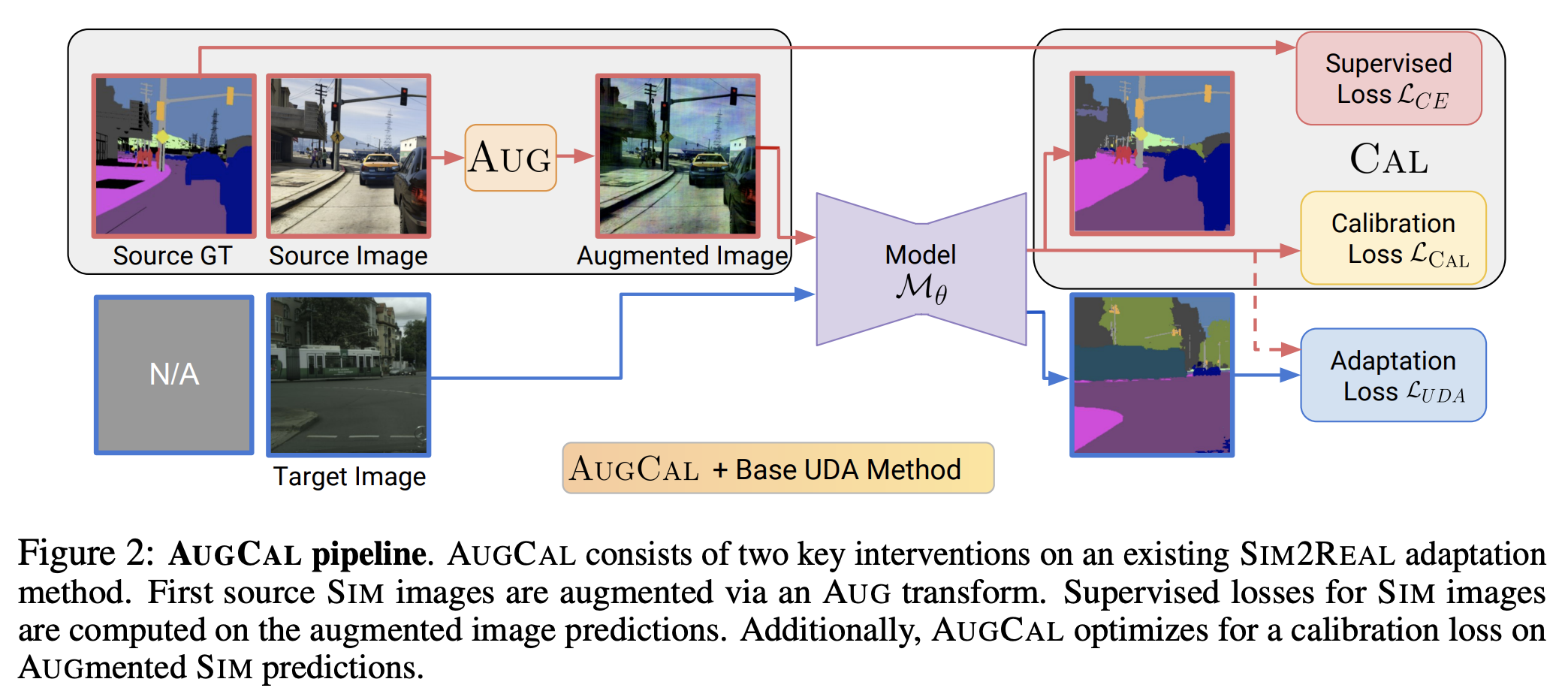
AUGCAL: Improving Sim2Real Adaptation by Uncertainty Calibration
on Augmented Synthetic Images
Prithvijit Chattopadhyay, Bharat Goyal, Boglarka Ecsedi, Viraj Prabhu, Judy Hoffman
ICLR 2024
Workshop on Uncertainty Quantification for Computer Vision, ICCV 2023 (Extended
Abstract)
[PDF]
[TL;DR]
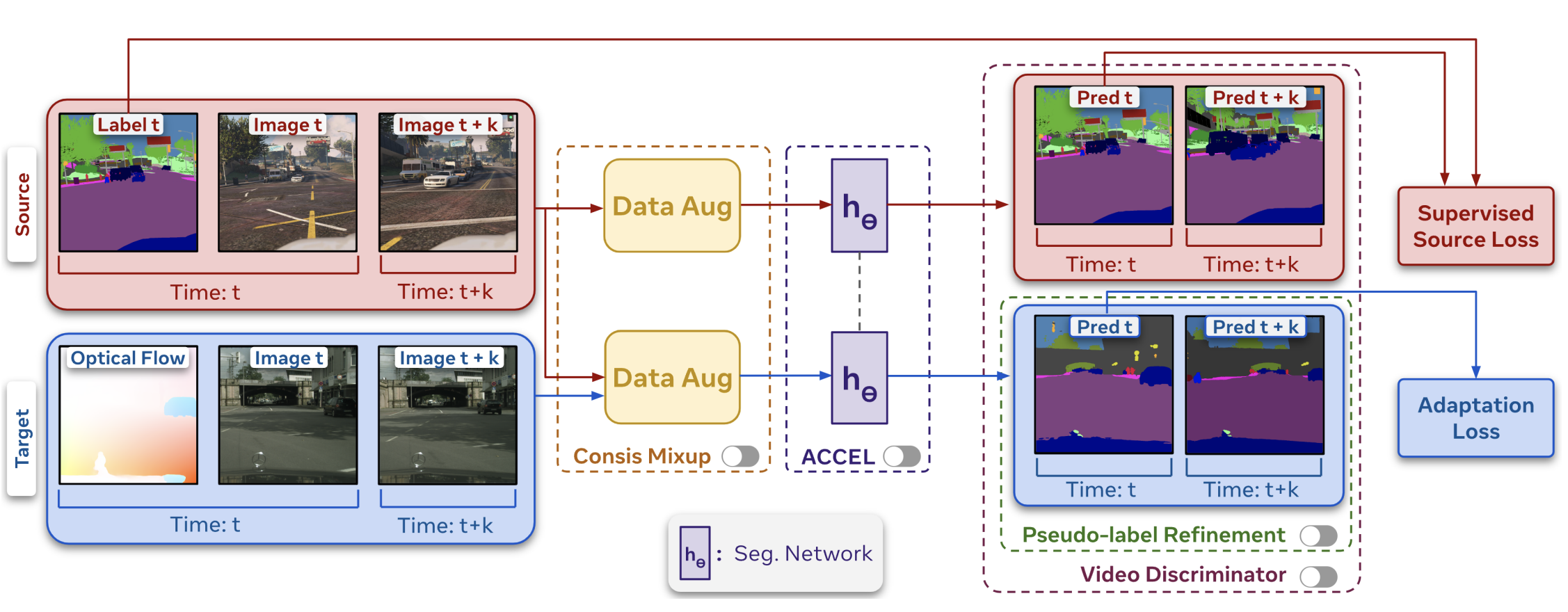
We're Not Using Videos Effectively: An Updated Domain Adaptive Video Segmentation
Baseline
Simar Kareer, Vivek Vijaykumar, Harsh Maheshwari, Prithvijit Chattopadhyay, Judy
Hoffman, Viraj Prabhu
TMLR 2024
[PDF]
[Code]
[TL;DR]
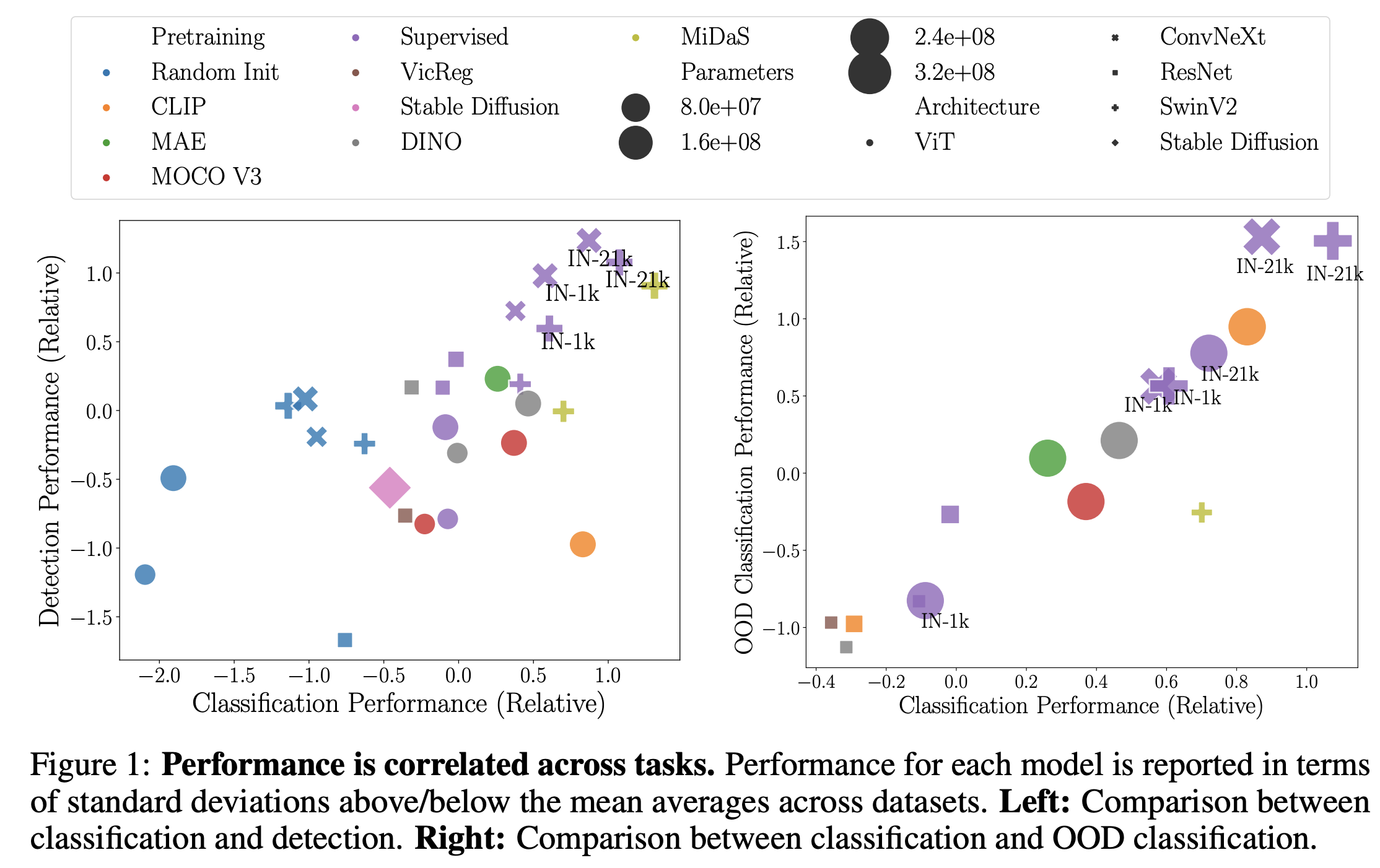
Battle of the Backbones: A Large-Scale Comparison of Pretrained
Models across Computer Vision Tasks
Micah Goldblum*, Hossein Souri*, Renkun Ni, Manli Shu, Viraj Uday Prabhu, Gowthami
Somepalli,
Prithvijit Chattopadhyay, Adrien Bardes, Mark Ibrahim, Judy Hoffman, Rama Chellappa, Andrew Gordon
Wilson, Tom Goldstein
NeurIPS Datasets and Benchmarks 2023
[PDF]
[Code]
[TL;DR]
LANCE: Stress-testing Visual Models by Generating
Language-guided
Counterfactual Images
Viraj Prabhu,
Sriram Yenamandra,
Prithvijit Chattopadhyay,
Judy Hoffman
NeurIPS 2023
[PDF]
[code]
[project page]
[TL;DR]

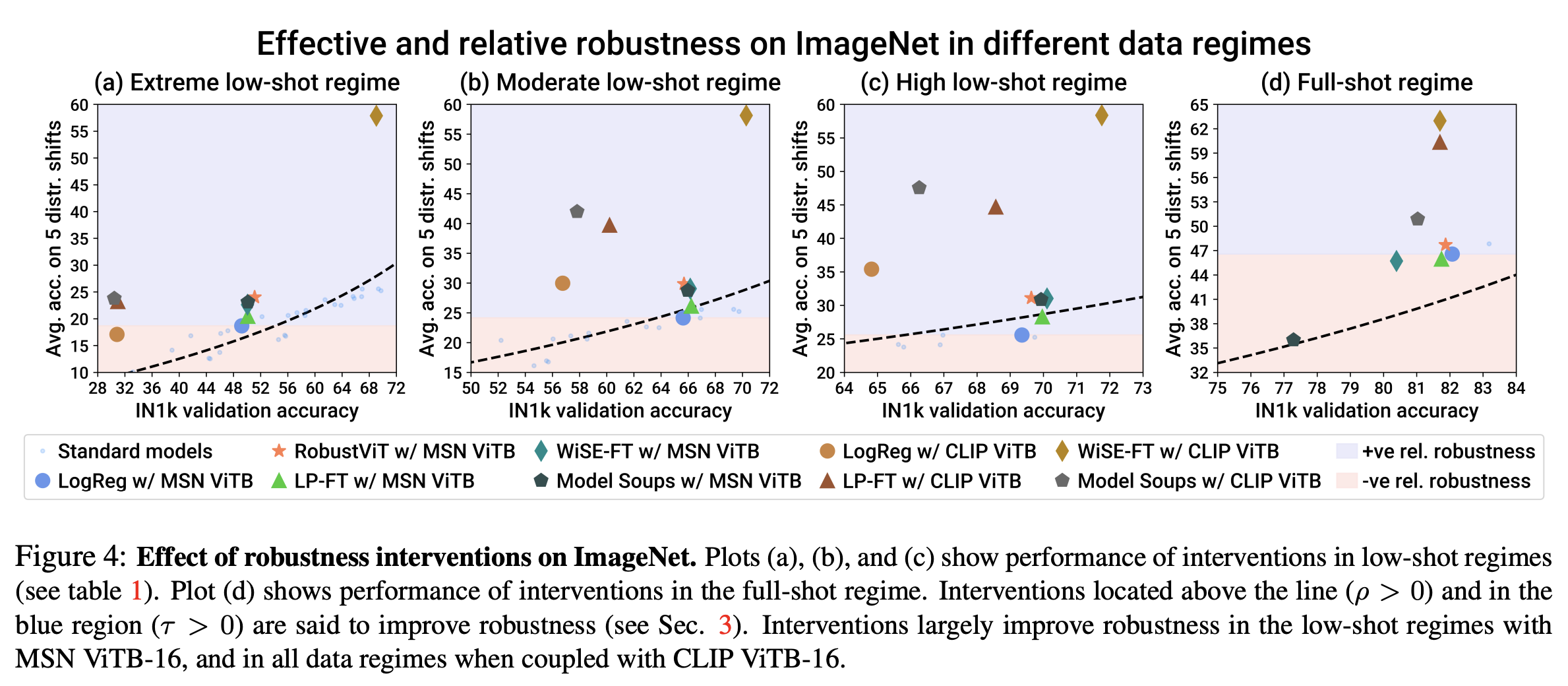
Benchmarking Low-Shot Robustness to Natural Distribution Shifts
Aaditya Singh,
Kartik Sarangmath,
Prithvijit Chattopadhyay,
Judy Hoffman
ICCV 2023
[PDF]
[code]
[TL;DR]
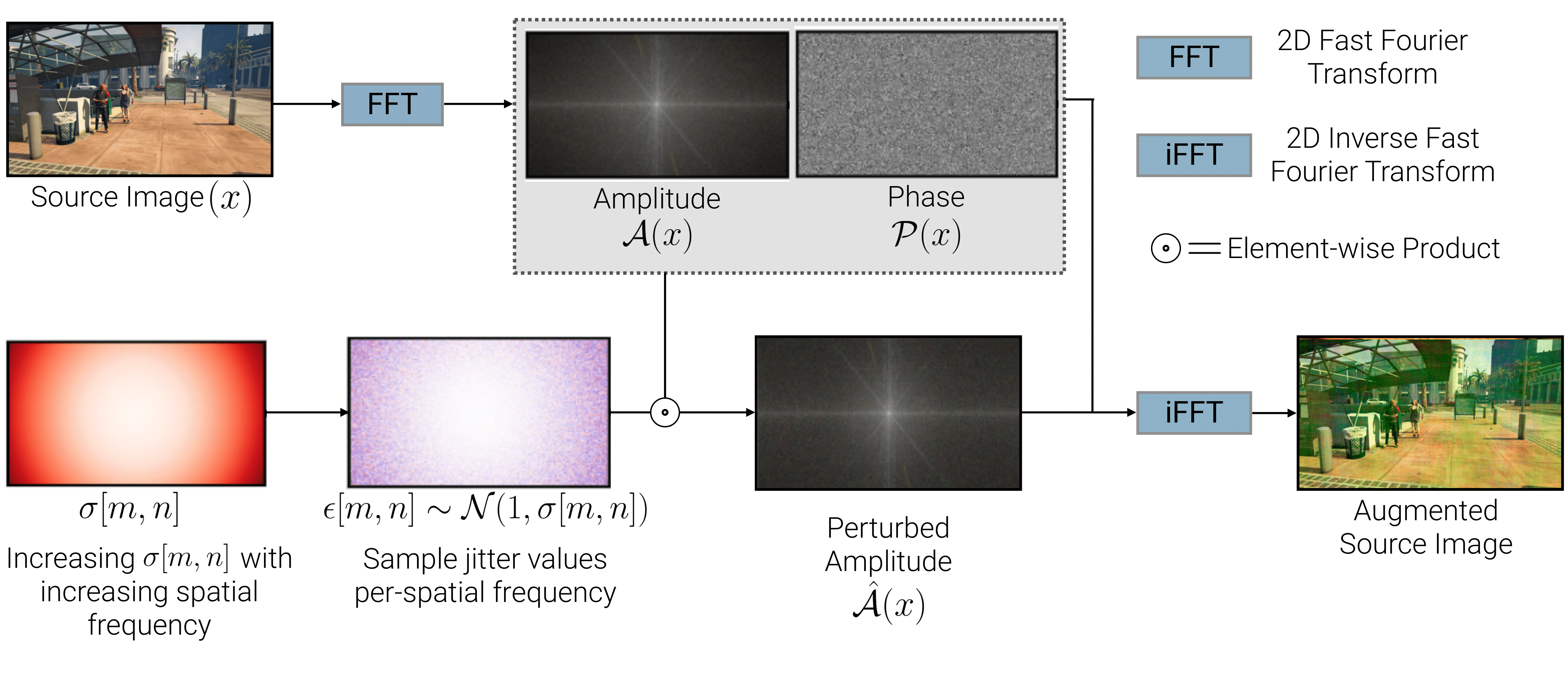
PASTA: Proportional Amplitude Spectrum Training Augmentation for
Syn-to-Real Domain Generalization
Prithvijit Chattopadhyay*,
Kartik Sarangmath*,
Vivek Vijaykumar,
Judy Hoffman
ICCV 2023
[PDF]
[code]
[TL;DR]
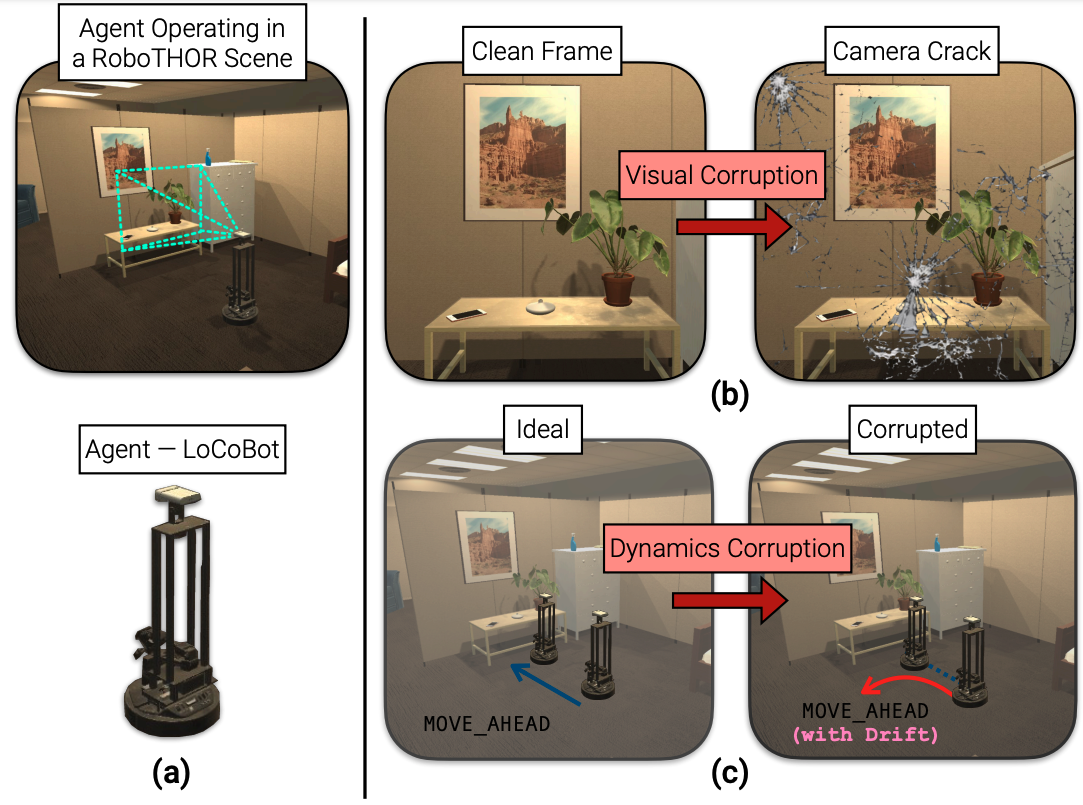
RobustNav: Towards Benchmarking Robustness in Embodied
Navigation
Prithvijit Chattopadhyay,
Judy Hoffman,
Roozbeh Mottaghi,
Ani Kembhavi
ICCV 2021
Oral presentation
[PDF]
[code]
[project page]
[video]
[TL;DR]
Likelihood Landscapes: A Unifying Principle Behind Many
Adversarial Defenses
Fu Lin,
Rohit Mittapali,
Prithvijit Chattopadhyay,
Daniel Bolya,
Judy Hoffman
Adversarial Robustness in the Real World (AROW), ECCV 2020
NVIDIA Best Paper Runner Up
[PDF]
[video]
[TL;DR]

Learning to Balance Specificity and Invariance for In and Out of
Domain Generalization
Prithvijit Chattopadhyay,
Yogesh Balaji,
Judy Hoffman
ECCV 2020
Visual Learning with Limited Labels (LwLL), CVPR 2020
[PDF]
[code]
[video]
[TL;DR]
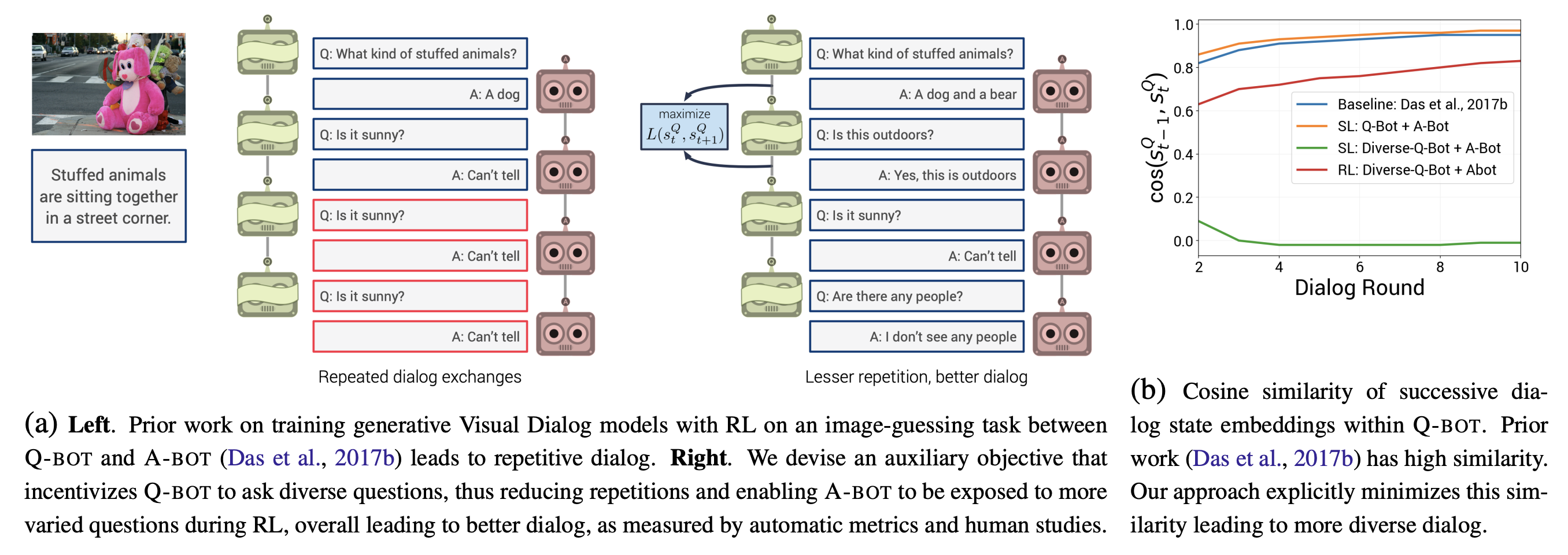
Improving Generative Visual Dialog by Answering Diverse
Questions
Vishvak Murahari,
Prithvijit Chattopadhyay,
Dhruv Batra,
Devi Parikh,
Abhishek Das
EMNLP 2019
Visual Question Answering and Dialog Workshop,
CVPR 2019
[PDF]
[code]
[TL;DR]
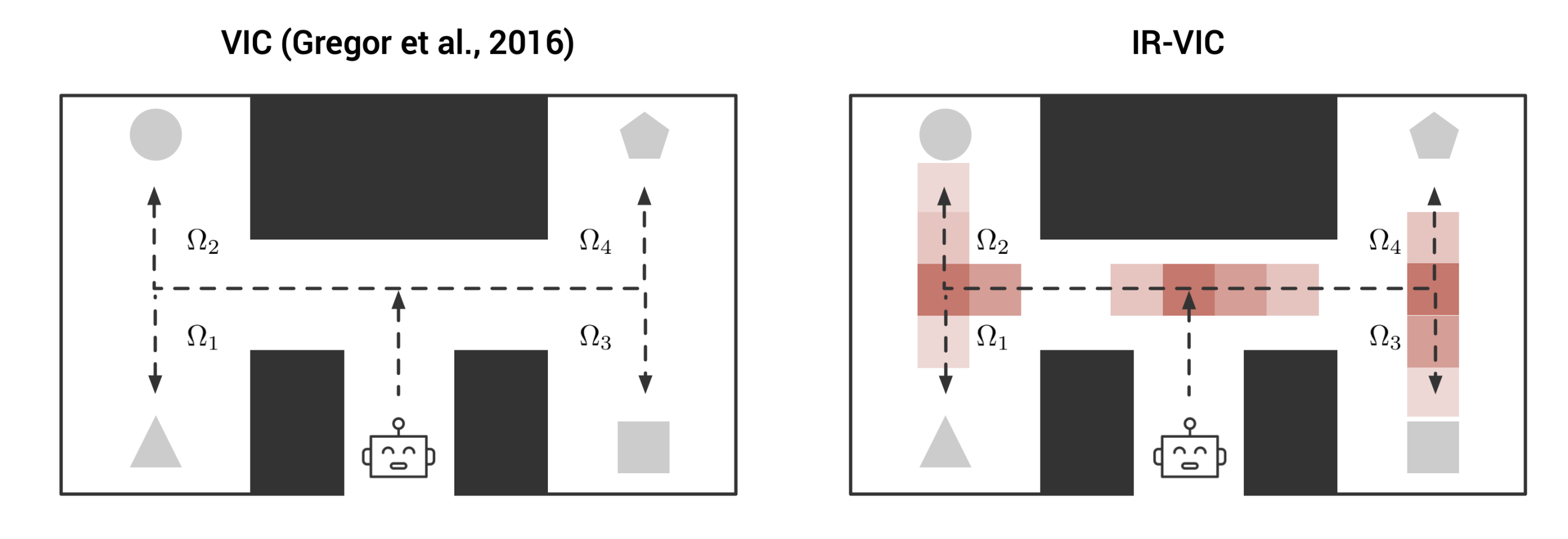
IR-VIC: Unsupervised Discovery of Sub-goals for Transfer in RL
Nirbhay Modhe,
Prithvijit Chattopadhyay,
Mohit Sharma,
Abhishek Das,
Devi Parikh,
Dhruv Batra,
Ramakrishna Vedantam
IJCAI 2020
Workshop on Task Agnostic Reinforcement Learning (TARL), ICLR 2019
[PDF]
[TL;DR]
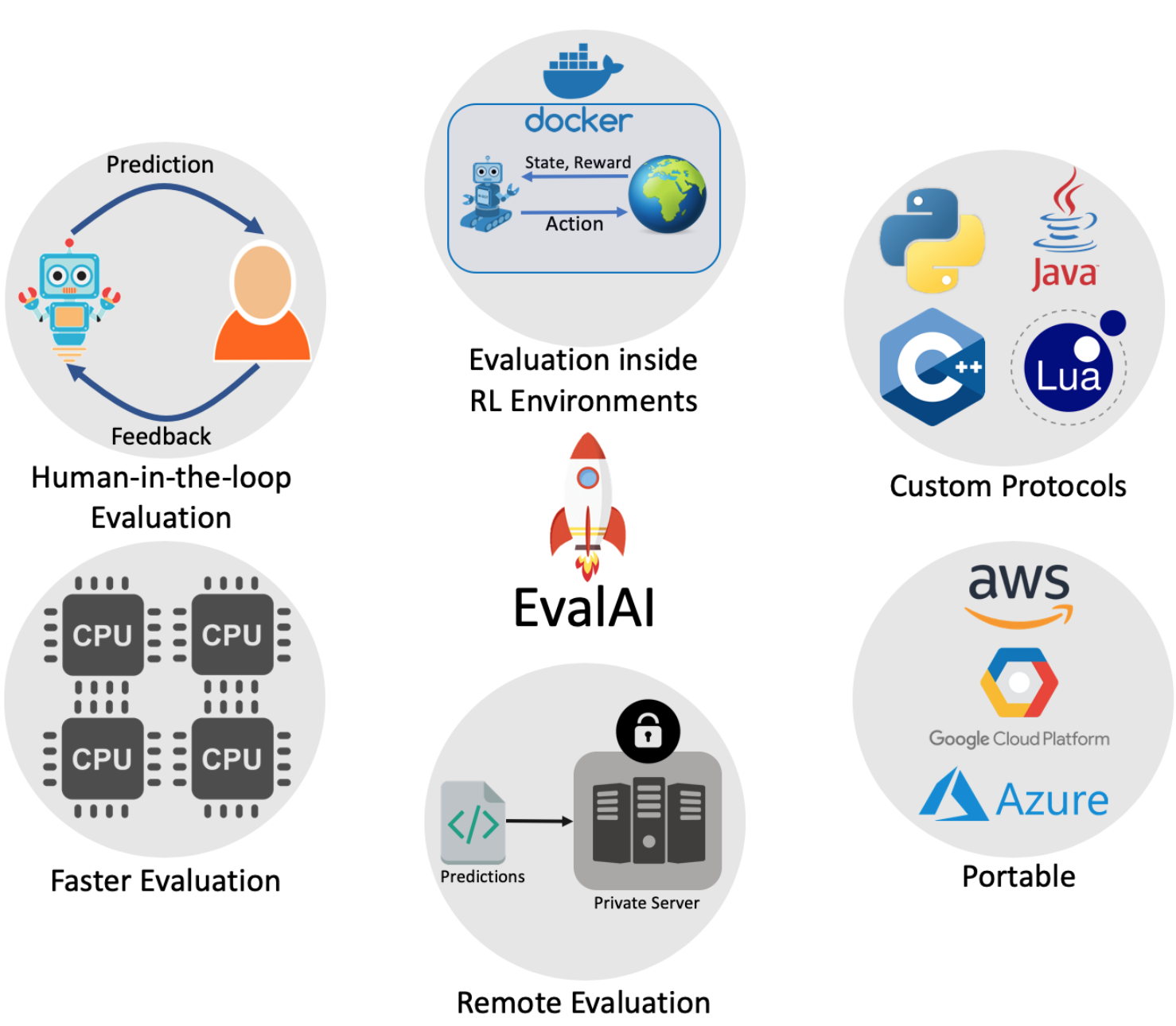
EvalAI: Towards Better Evaluation Systems for AI Agents
Deshraj Yadav,
Rishabh Jain,
Harsh Agrawal,
Prithvijit Chattopadhyay,
Taranjeet Singh,
Akash Jain,
Shiv Baran Singh,
Stefan Lee,
Dhruv Batra
Workshop on AI Systems, SOSP 2019
[PDF]
[code]
[TL;DR]
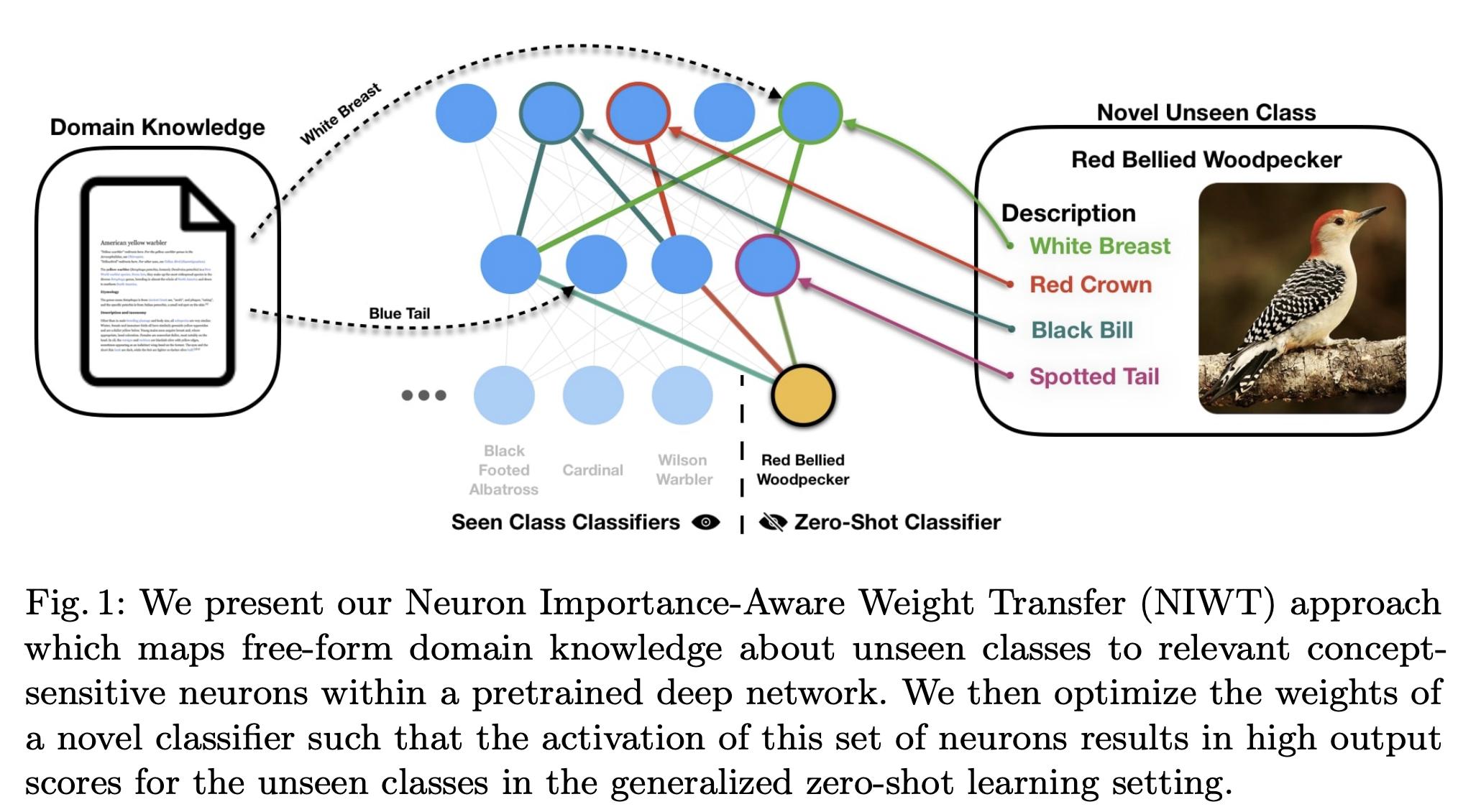
Choose Your Neuron: Incorporating Domain-Knowledge through
Neuron-Importance
Ramprasaath R. Selvaraju*,
Prithvijit Chattopadhyay*,
Mohamed Elhoseiny,
Tilak Sharma,
Dhruv Batra,
Devi Parikh,
Stefan Lee
ECCV, 2018
Continual Learning Workshop, NeurIPS 2018
Visually Grounded Interaction and Language (ViGIL) Workshop, NeurIPS 2018
[PDF]
[code]
[article]
[TL;DR]
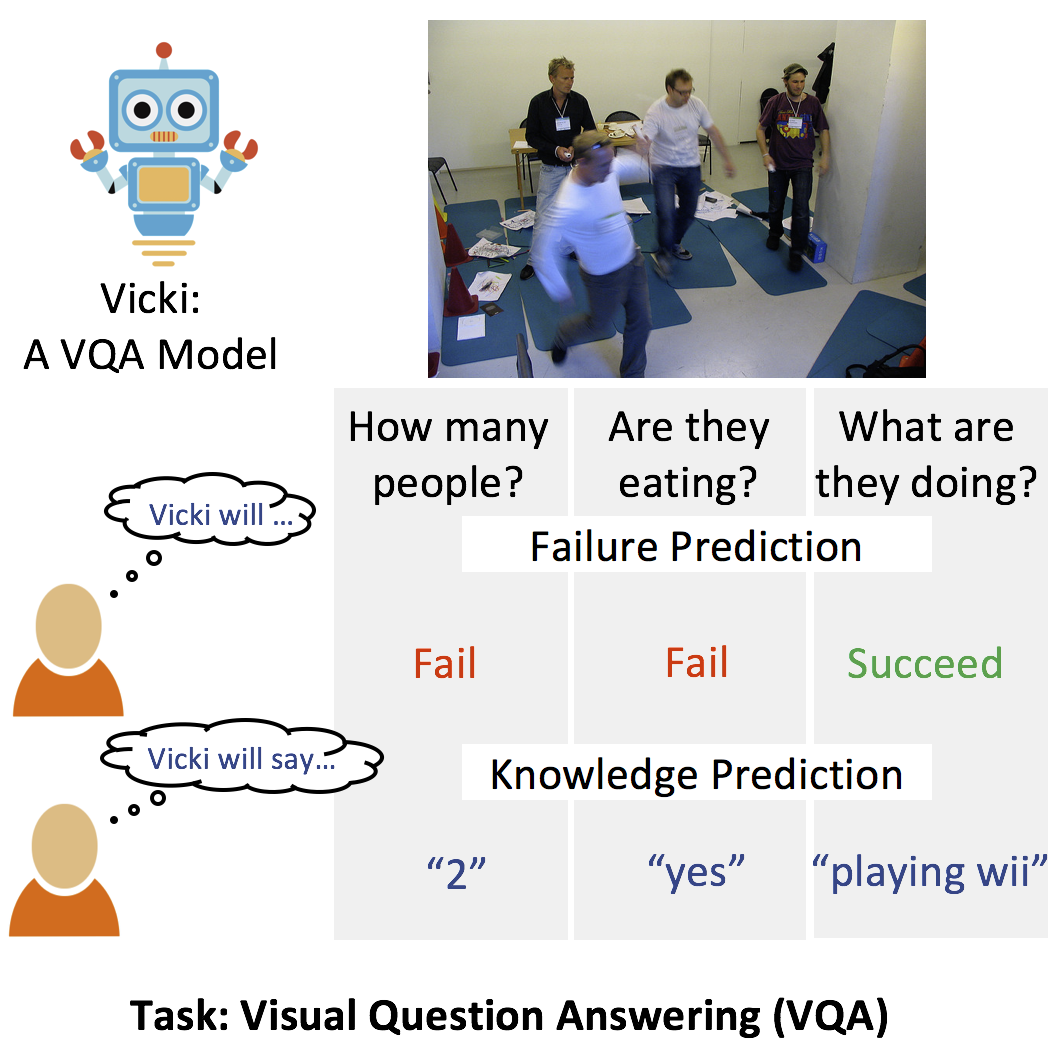
Do explanation modalities make VQA Models more predictable to a
human?
Arjun Chandrasekaran*,
Viraj Prabhu*,
Deshraj Yadav*,
Prithvijit Chattopadhyay*,
Devi Parikh
EMNLP 2018
[PDF]
[TL;DR]
Evaluating Visual Conversational Agents via Cooperative Human-AI
Games
Prithvijit Chattopadhyay*,
Deshraj Yadav*,
Viraj Prabhu,
Arjun Chandrasekaran,
Abhishek Das,
Stefan Lee,
Dhruv Batra,
Devi Parikh
HCOMP 2017
Oral presentation
[PDF]
[code]
[TL;DR]
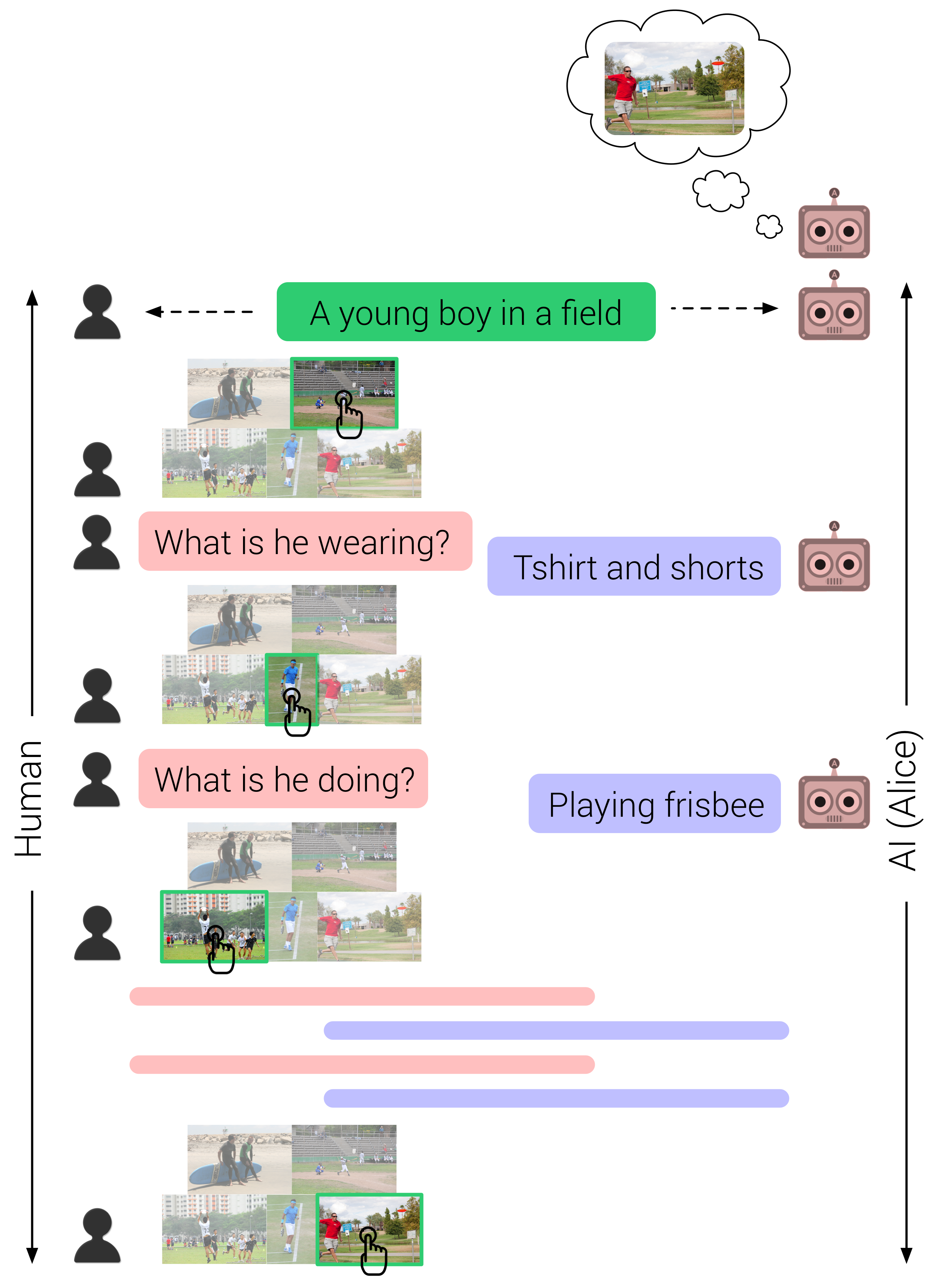
It Takes Two to Tango: Towards Theory of AI's Mind
Arjun Chandrasekaranu*,
Deshraj Yadav*,
Prithvijit Chattopadhyay*,
Viraj Prabhu*,
Devi Parikh
Chalearn Looking at People Workshop, CVPR 2017
[PDF]
[code]
[TL;DR]
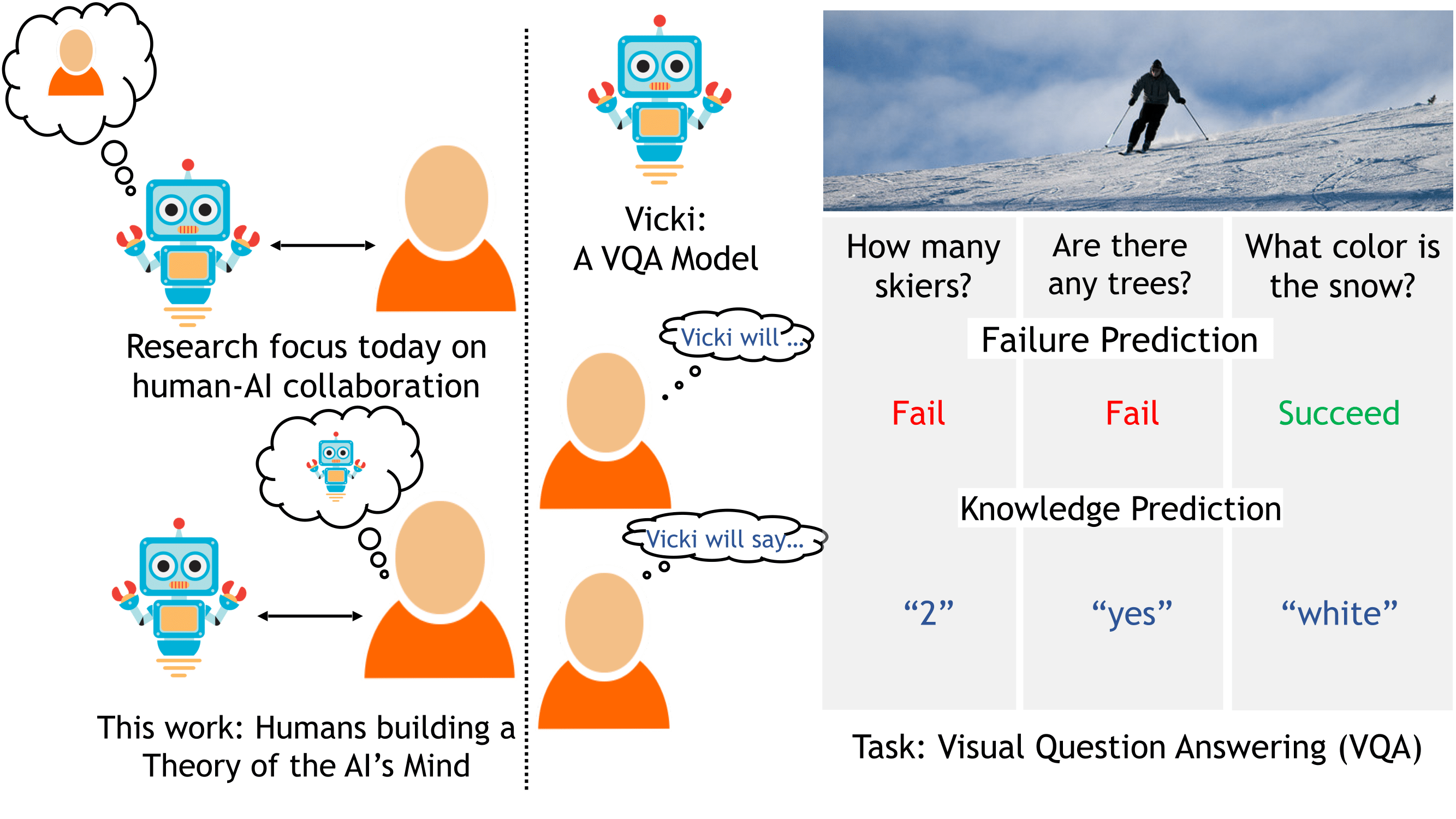
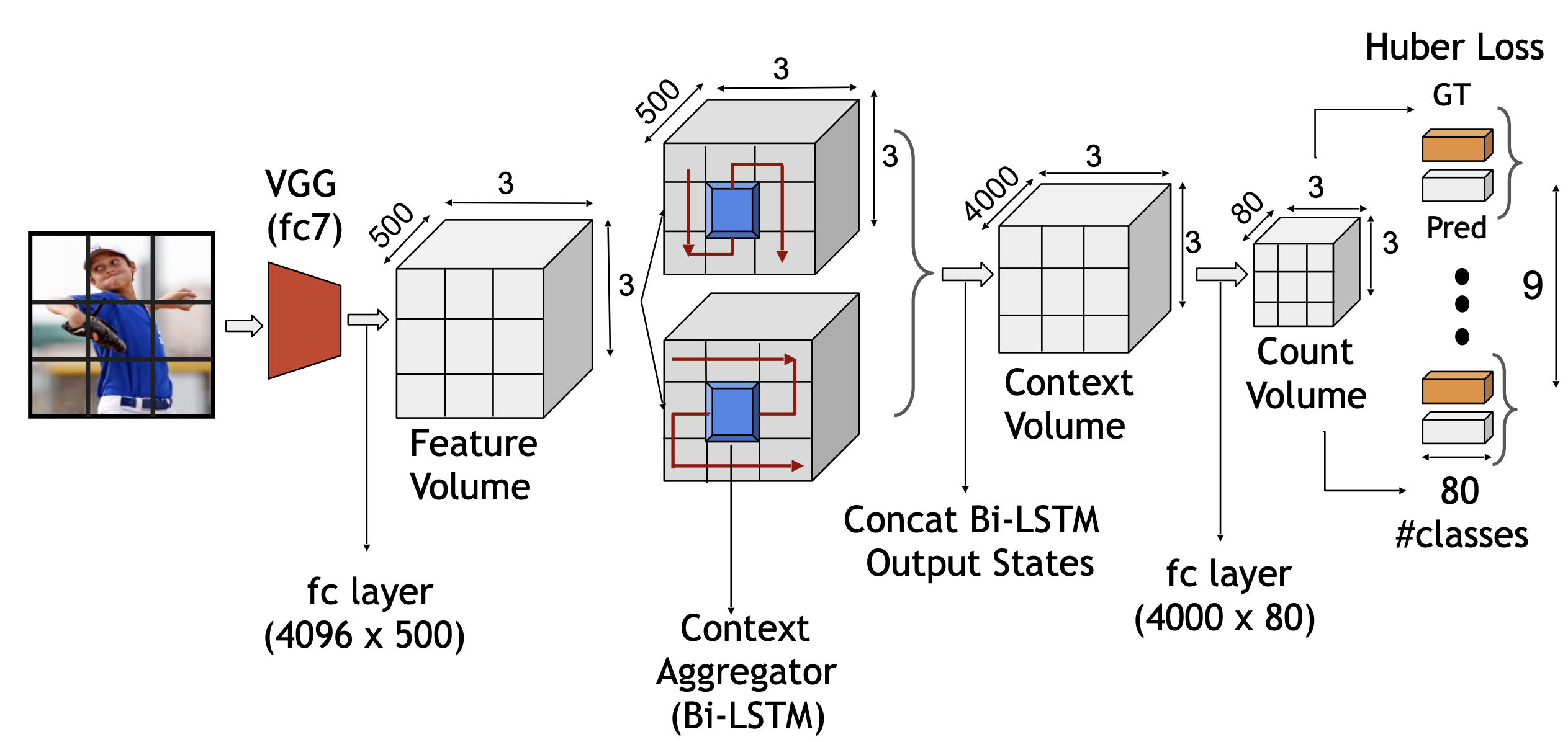
Counting Everyday Objects in Everyday Scenes
Prithvijit Chattopadhyay*,
Ramakrishna Vedantam*,
Ramprasaath R. Selvaraju,
Dhruv Batra,
Devi Parikh
CVPR 2017
Spotlight presentation
[PDF]
[code]
[TL;DR]
Projects
Investigating Visual Dialog Models for Goal-Driven Self-Talk Prithvijit Chattopadhyay (advised by Devi Parikh) 2019 [Report PDF]
Exploring Weak-Supervision and Generative Models for Semantic Segmentation 2018 Prithvijit Chattopadhyay, Ramprasaath R. Selvaraju, Viraj Prabhu [Report PDF]
DTU AUV: Autonomous Underwater Vehicle Prithvijit Chattopadhyay (Acoustics & Control Systems Department) (co-authored with DTU AUV members) 2012-2016 [Report PDF]
Theses
Evaluating Visual Conversational Agents in the Context of Human-AI Cooperative Games Masters in Computer Science (specialization Machine Learning) 2017-2019 [PDF]
Professional Services
Reviewing: CVPR 2018-23, ICCV 2023, ICRA 2021-22, ECCV 2018, NeurIPS 2018-21,23, ICLR 2019-22, ICML 2019-20, ACL 2019, TPAMI
(Design and CSS Courtesy: Shiori Sagawa)