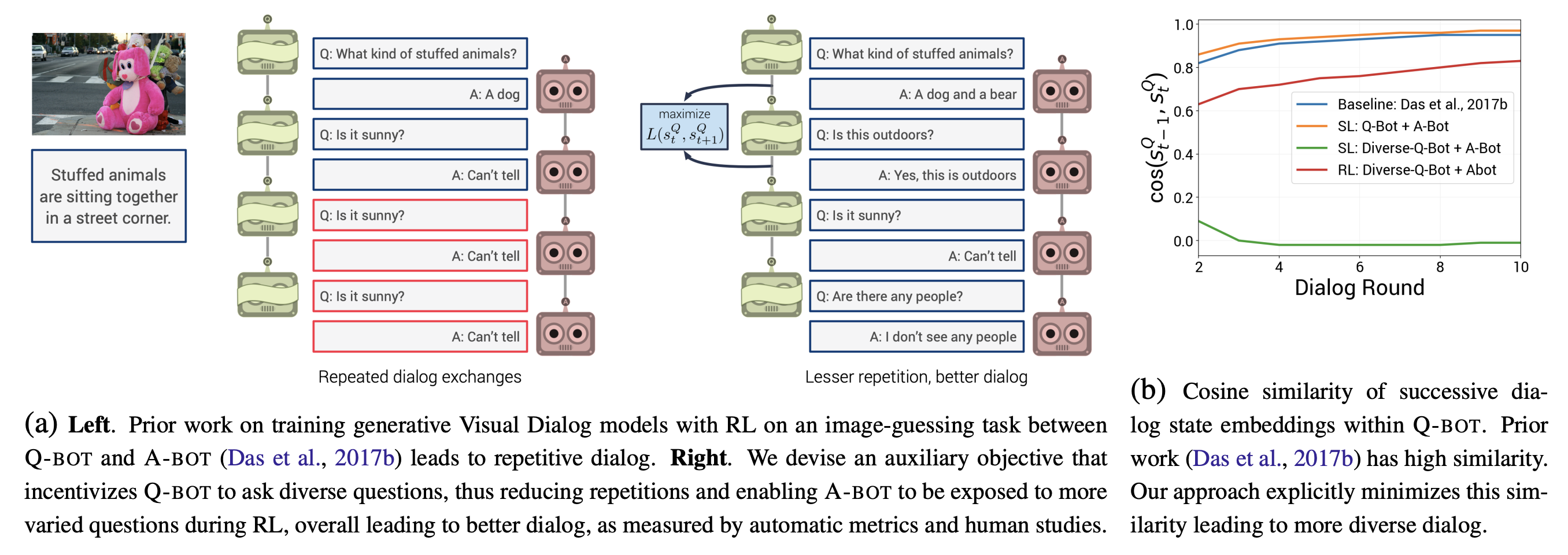
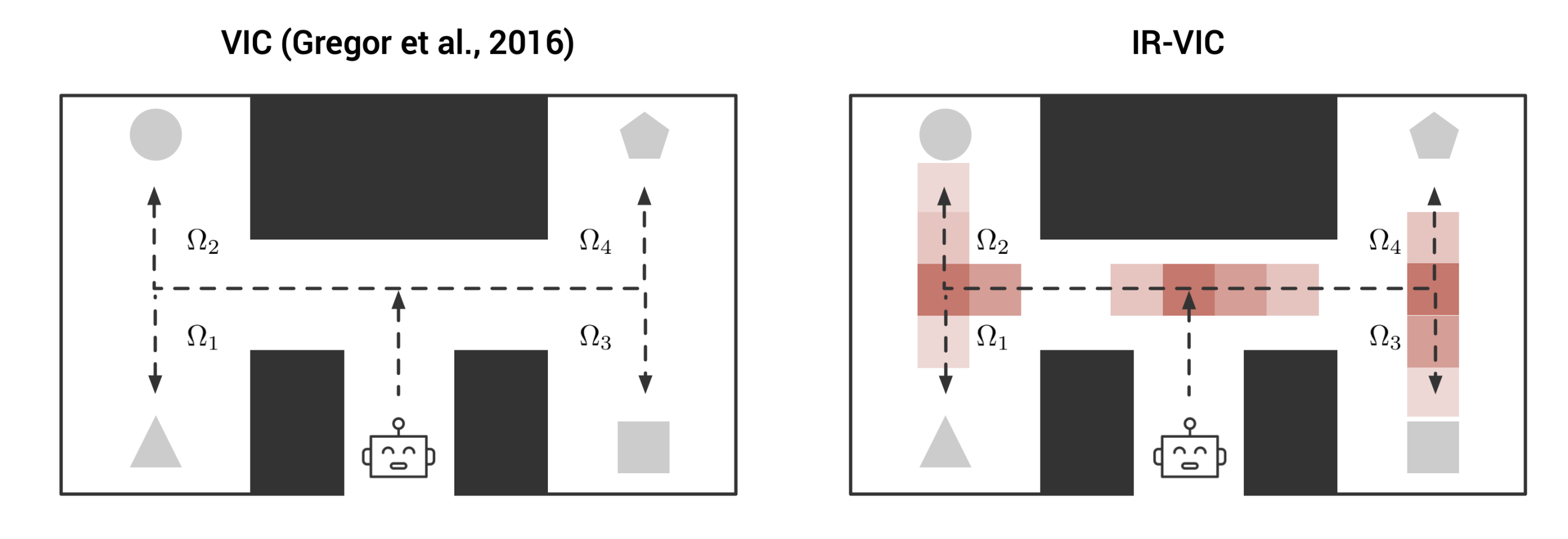
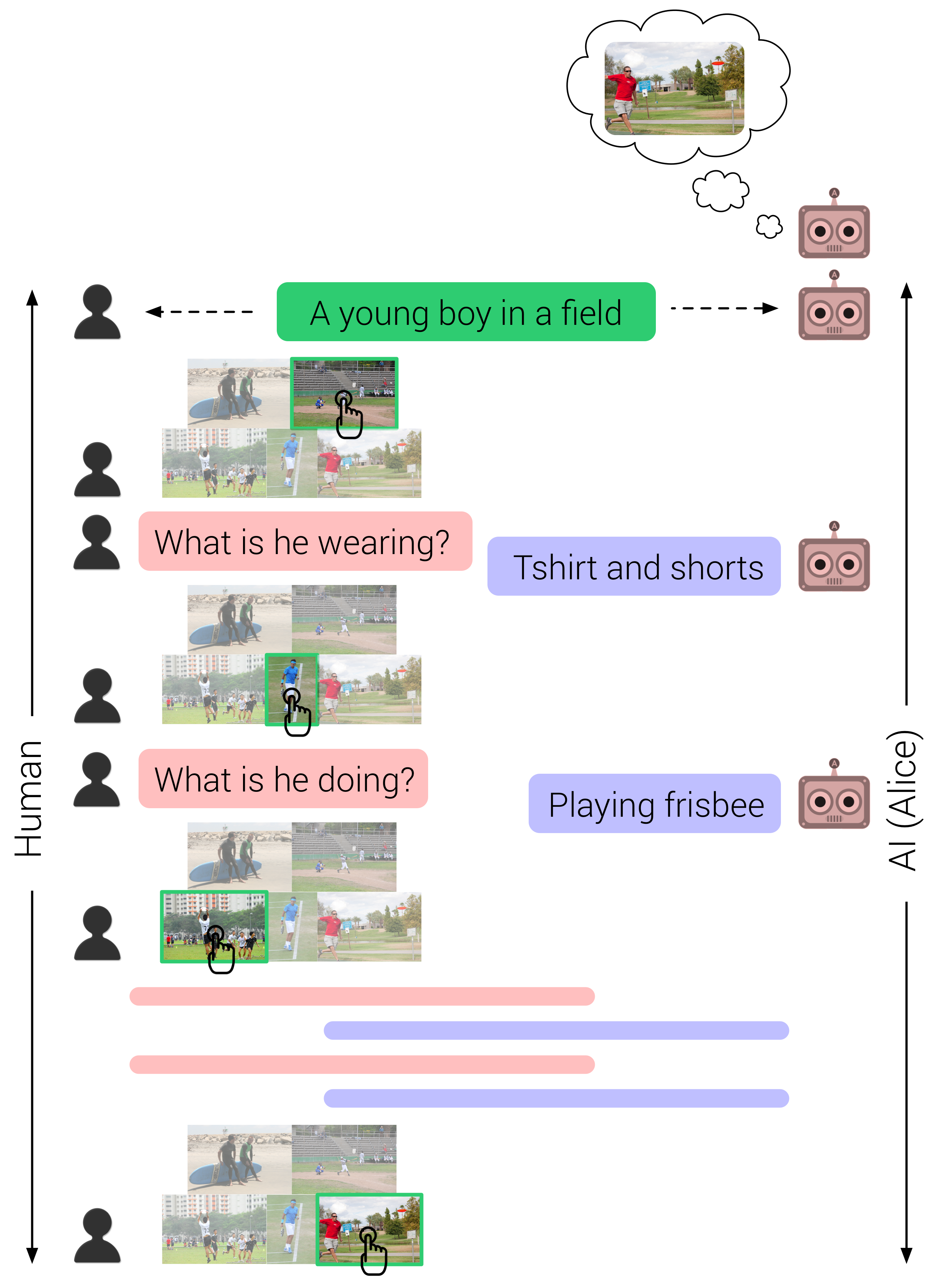
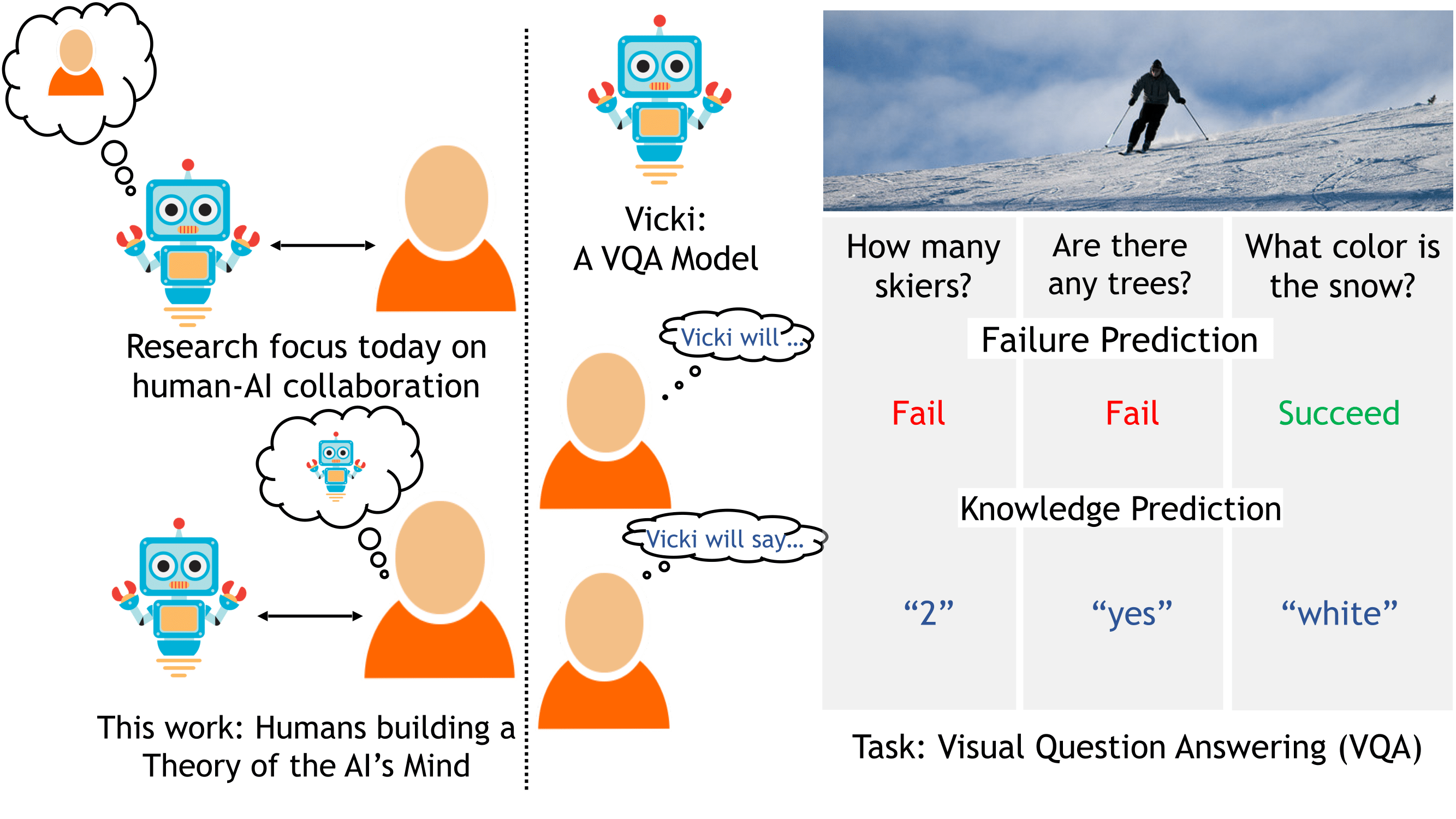
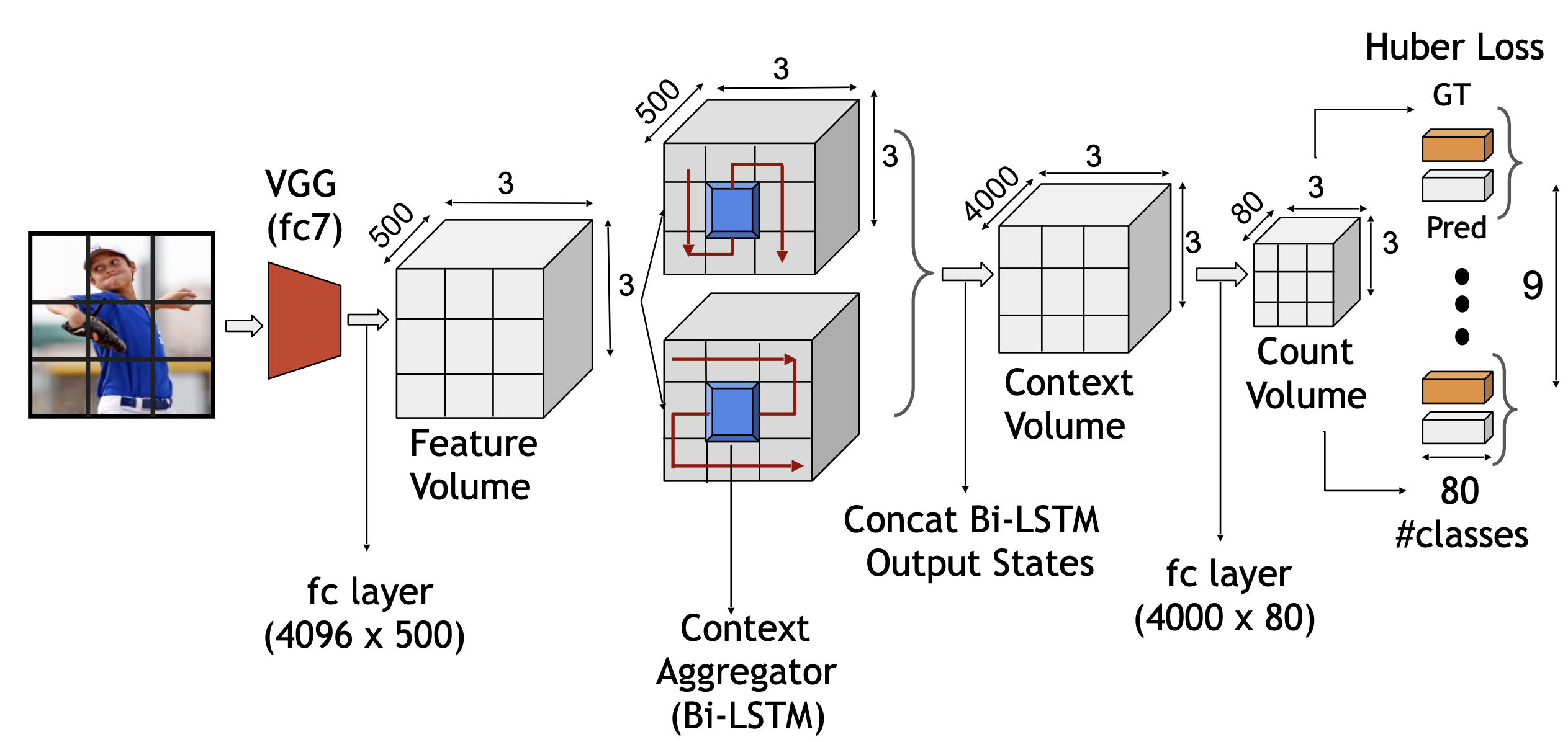
Investigating Visual Dialog Models for Goal-Driven Self-Talk
2019

Research Scientist, NVIDIA Cosmos Lab
Ph.D., Georgia Tech (2019–2024)
advised by Judy Hoffman
★ Rising Star Doctoral Student Award
M.S., Georgia Tech (2017–2019)
advised by Devi Parikh
I am a Research Scientist at NVIDIA Cosmos Lab, where I work on world-foundation models: video-generation models for spatio-temporal forecasting and VLMs for understanding. My work spans model-design, pre-training, data curation and evaluation of large multi-modal foundation models.
I'm driven by challenging open-ended problems that stretch what I know. Besides the usual research grind, my latest obsessions are.
My past work has spanned core computer vision (generalization, robustness, learning from limited supervision or synthetic data), the intersection of computer vision and language, and embodied AI.
I also actively participate in reviewing for top computer vision and machine learning conferences & workshops (have accumulated a few reviewer awards — ICCV 2025, CVPR 2023, CVPR 2022, CVPR 2021, ICLR 2022, MLRC 2021, ICML 2020, NeurIPS 2019, ICLR 2019, NeurIPS 2018 - in the process).
2024–Present
Summer 2020, 2022
Summer 2018

2017-2024

2016-2017
Winter 2014

2012-2016
(* indicates equal contribution)